The AI-powered Ask LukeW feature on this site has been updated to not only source answers from Web pages but also audio files and videos. Today we're adding PDF support for 370+ presentations, which required some new approaches that I'll detail below.
The Ask LukeW feature is powered by AI models that break down content into related concepts and reassemble it into new answers. When that content is sourced from a Web page, audio file, or video file, we cite it and give you the ability to go deeper into the original source file.
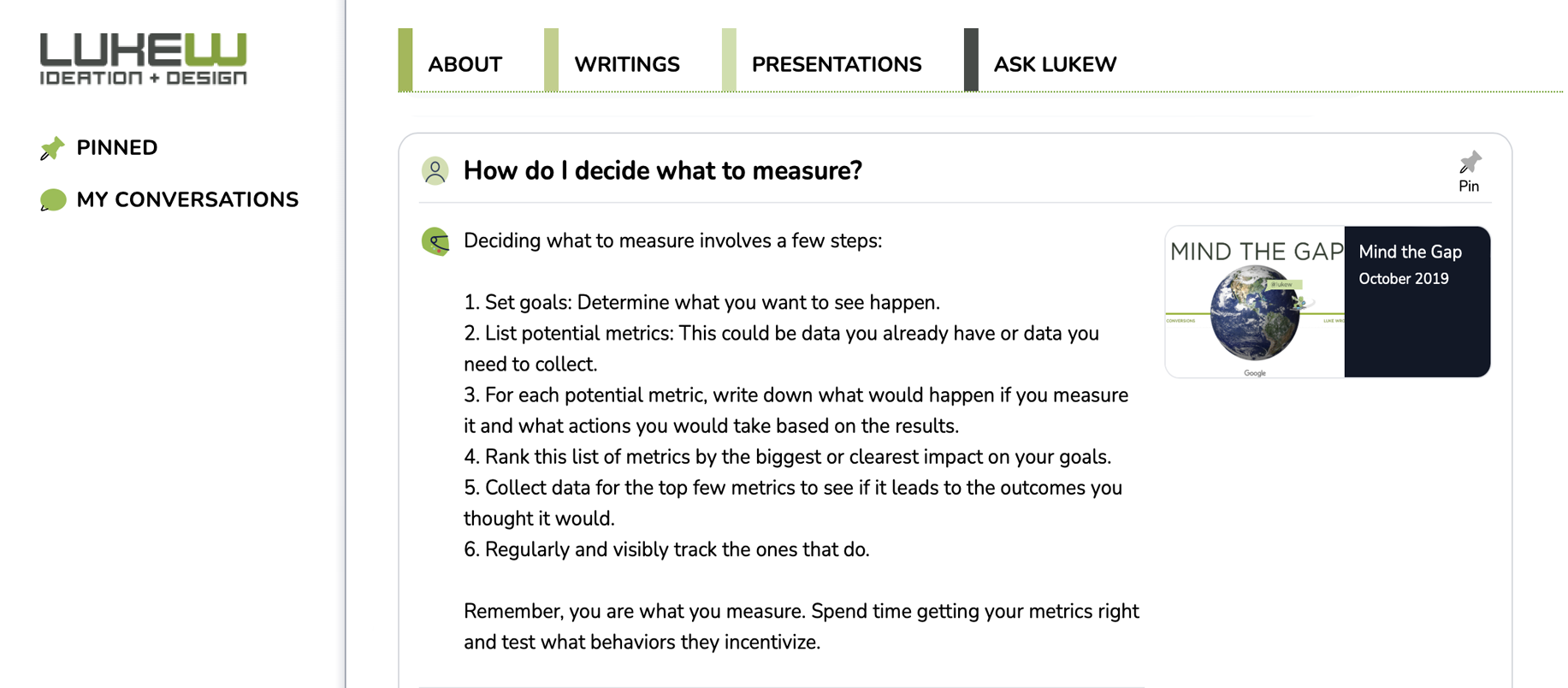
When adding PDF content, we made use of the same structure and cite any PDF documents used to answer questions in the source card to the right (example above). Selecting one of these cards opens an integrated (within the broader conversational UI) PDF experience that looks like this:
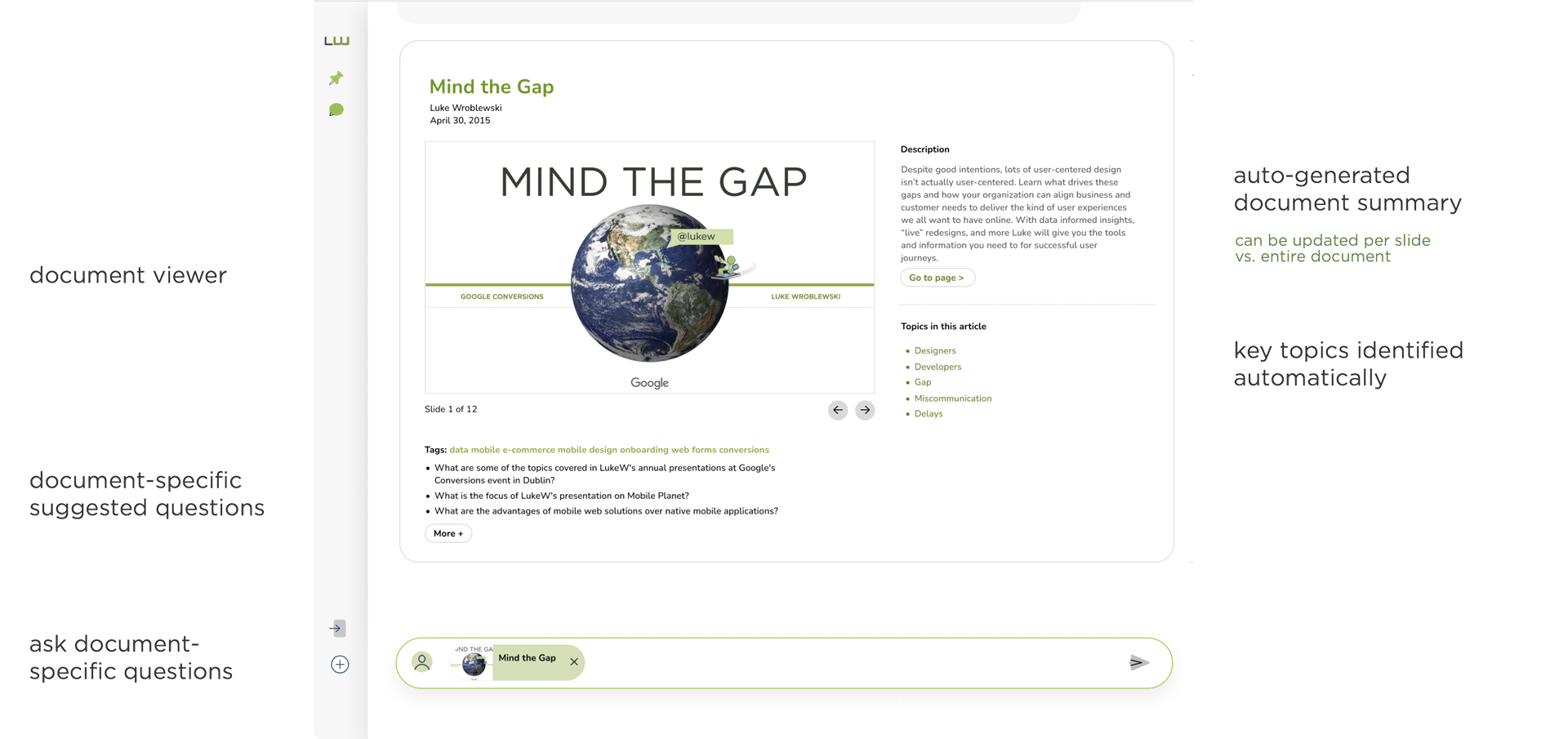
This mirrors how we treat Web pages, audio files, and videos as well. Like these other media types, for each PDF file integrated within Ask LukeW, we make use of LLM language operations to:
- summarize the PDF file
- create follow-on questions to ask based on the content of the PDF file
- enable people to ask questions using just the content within the PDF file
- generate answers in response to what people ask
But PDFs are special
Web page content is fairly easy to parse especially when the pages are written with minimal and semantically meaningful HTML. Audio and video files require more work as we need to generate transcripts, diarize them to separate speakers, and more. But these processes mostly yield good content that can be used to answer people's questions with AI. PDFs too? Well, kind of.
PDF files encapsulate a complete description of not just the content of a document but its layout as well. So parsing them is more challenging, especially when you want to retain the information in tables that's really stored as layout. The end result is parsed PDF files tend to be quite large (especially when 100+ slides like my talks) and often contain junk content.
What does this mean for Ask LukeW answers that cite PDFs? Their large size can quickly fill up the available space (context window) of large language models (LLMs) thereby crowding out other files like Web pages, videos, etc. And the junk content within them can leading to unintended results in answers. Though largely, LLMs are pretty good at ignoring irrelevant content so this is less of an issue.
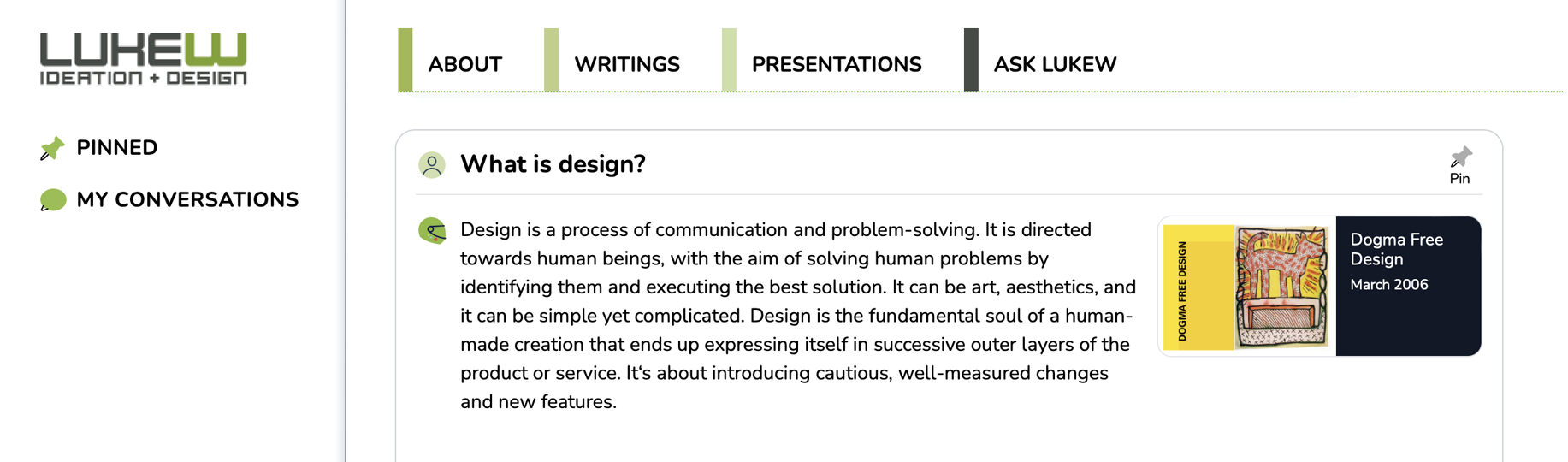
You can see the impact of adding PDFs to the Ask LukeW index in the example below. The first answer to "What is design?" comes from an index without PDF files.
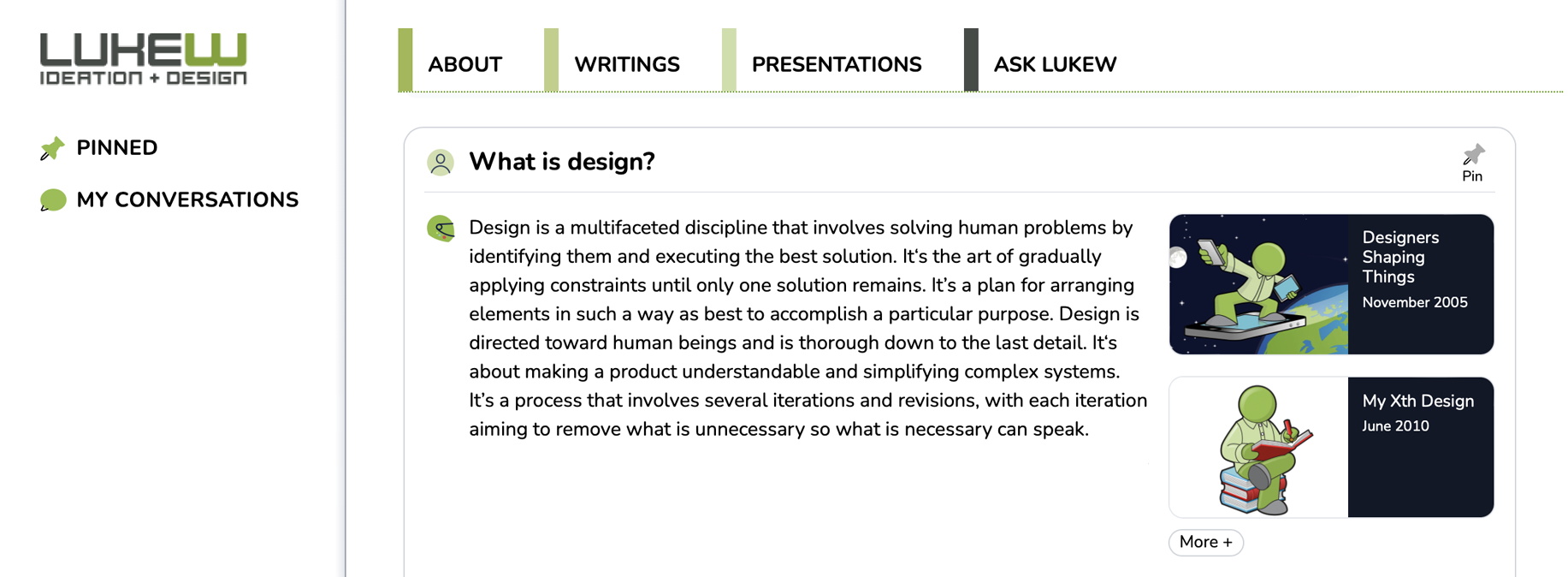
When PDFs were added, a presentation from 2006 with lots of quotes defining design significantly impacted the answer. Other sources were no longer being considered due to the PDF's size and perceived relevance (so many quotes about design!).
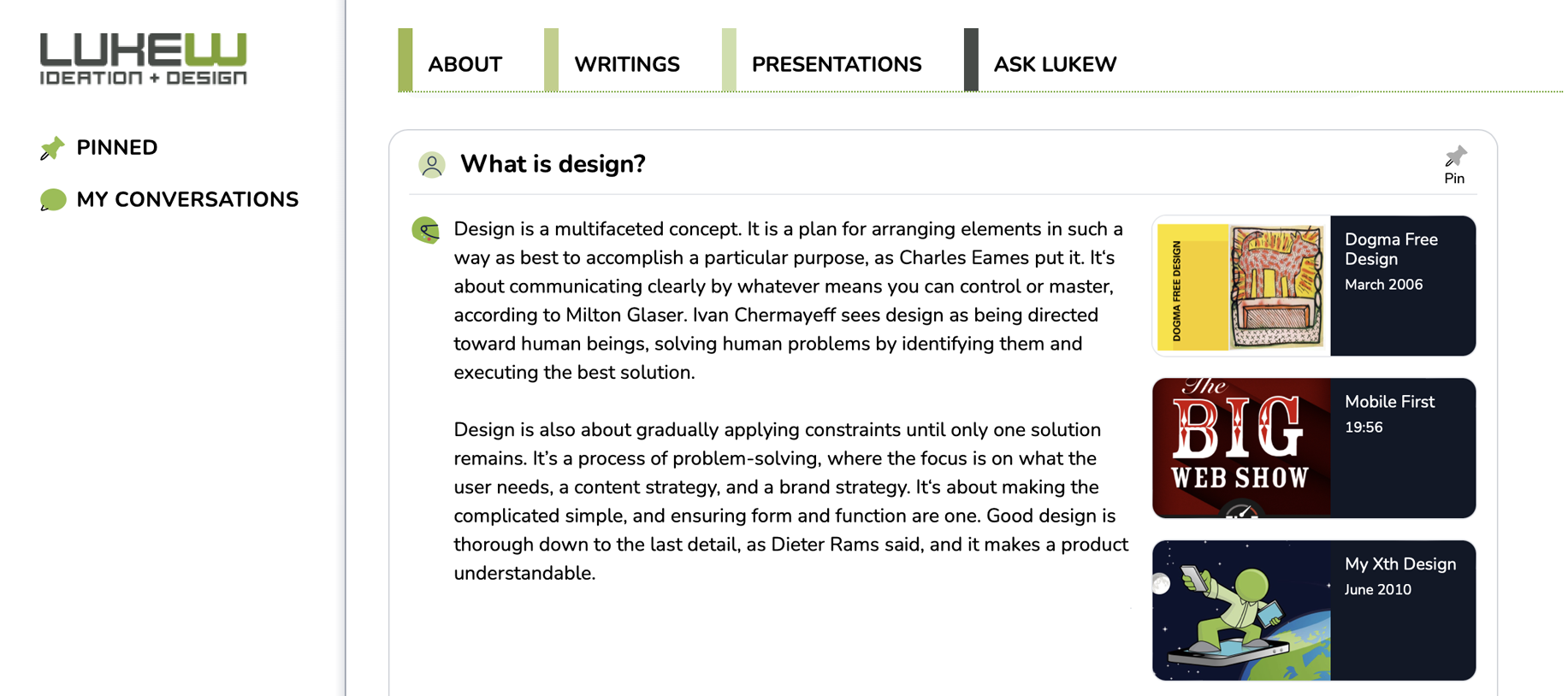
To account for this, we made two changes. First, we parsed PDFs page by page and created a separate entry for each. Next we calculated a quality score for each PDF page and removed ones that didn't meet a generous threshold. To calculate this quality score we took an open source language model, fed it examples of our questions and documents, and looked at which documents the model never paid attention to when generating its answer. This mostly got rid of the junk and still kept useful PDF content just in more appropriate chunks.
The end result is when people Ask LukeW "what is design?" now, they are getting an answer that not only cites the 2006 presentation that overwhelmed our answer before but audio files and Web pages as well. Hopefully resulting in a more complete and useful answer.
For more on how we've designed and built AI capabilities into this site, check out these earlier articles or just Ask Luke what you want to know.
Further Reading
- New Ways into Web Content: how AI enables a different way of interacting with a Web site
- Integrated Audio Experiences & Memory: enabling specific content experiences within a conversational UI
- Expanding Conversational User Interfaces: extending chat user interfaces to better support AI capabilities
- Integrated Video Experiences: adding video-specific experiences within conversational UI
As always, much thanks to Yangguang Li (front end), Thanh Tran (design), and Alex Peysakhovich (AI research) in helping make these updates possible.