We've added a few new updates to the Ask LukeW feature on this site powered by large language models (AI) including an integrated audio experience, conversation memory, and more. Here's the details:
Over the years, I've had the pleasure of appearing on many podcasts and panels about UI and digital product design. When possible, I published links to these conversations on this site: adding up to over 70 hours of audio. Don't worry. I haven't listened to it all. And now... you don't have to either.
There's information in these conversations that doesn't exist in other formats (articles, PDFs, etc.), so we spent some time adding them to the embedding index of content powering Ask LukeW. Casual conversations are often not as information-dense as topically-focused written articles, so several adjustments were needed to pull relevant bits from these long audio files into useful responses.
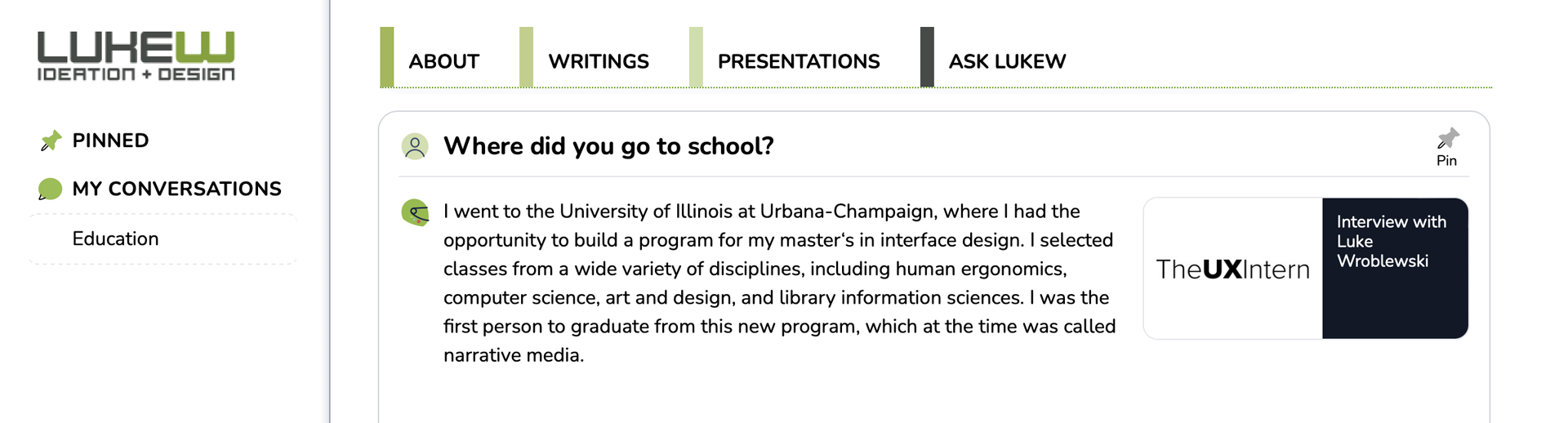
In the example above, the information about my studies at the University of Illinois comes from a interview I did on the UX Intern podcast. Pretty sure I wasn't this concise in the original podcast which is linked to in the source card to the right if you want to check.
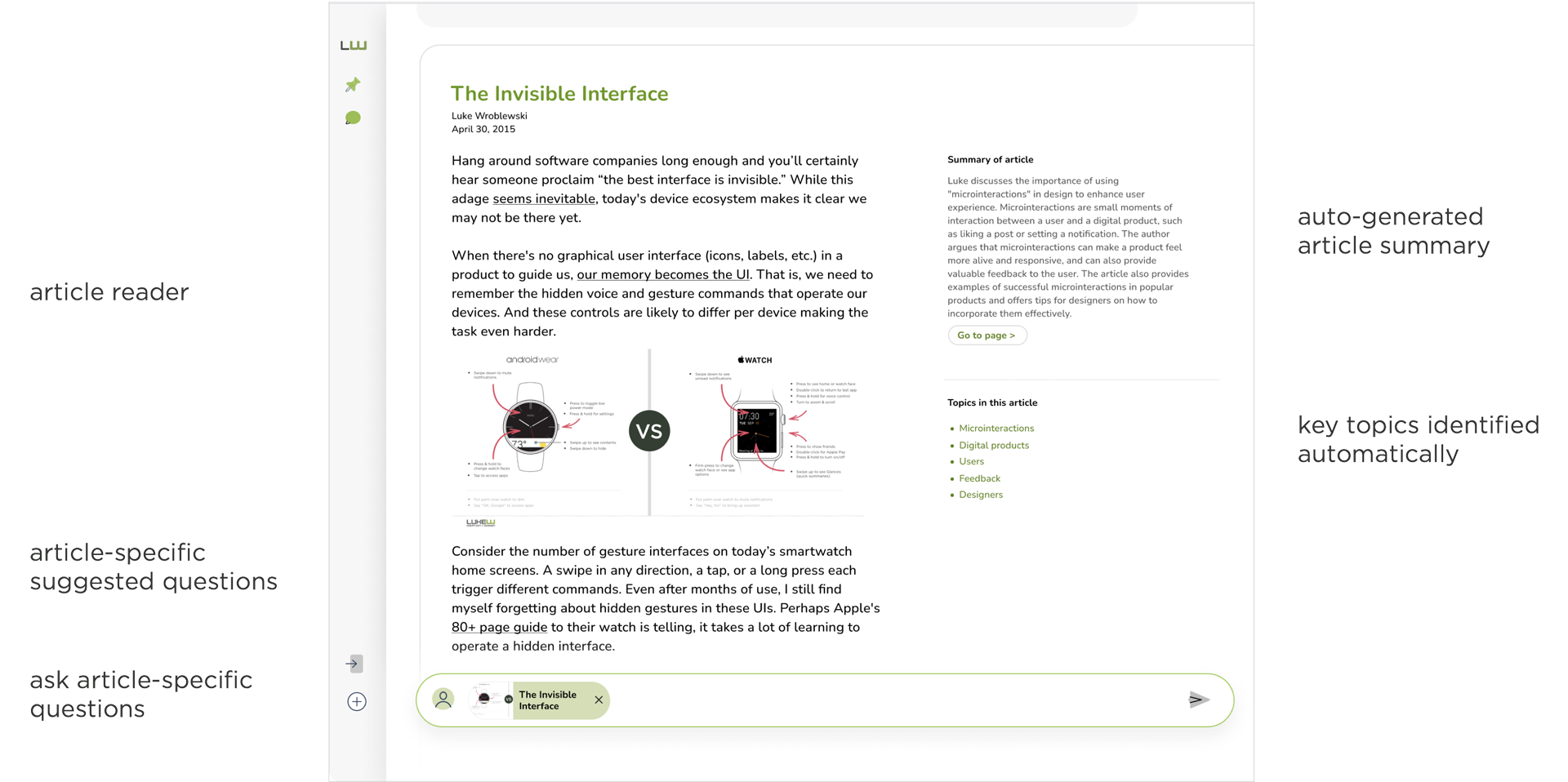
For each article sourced within Ask LukeW, we make use of large language model (LLM) operations to:
- summarize the article
- extract key topics from the article
- create follow-on questions to ask within each article
- enable people to ask questions using the content within the article
- generate answers in response to what people ask
The integrated (within the broader conversational UI) article experience looks like this:
Similarly for each audio file presented within Ask LukeW, we make use of LLM language operations to:
- summarize the audio file
- extract speakers, locations, key topics, and even generate a title from the audio file (if we lack the data)
- create follow-on questions to ask based on the content of the audio file
- enable people to ask questions using the content within the audio file
- generate answers in response to what people ask
The integrated audio experience looks like this:
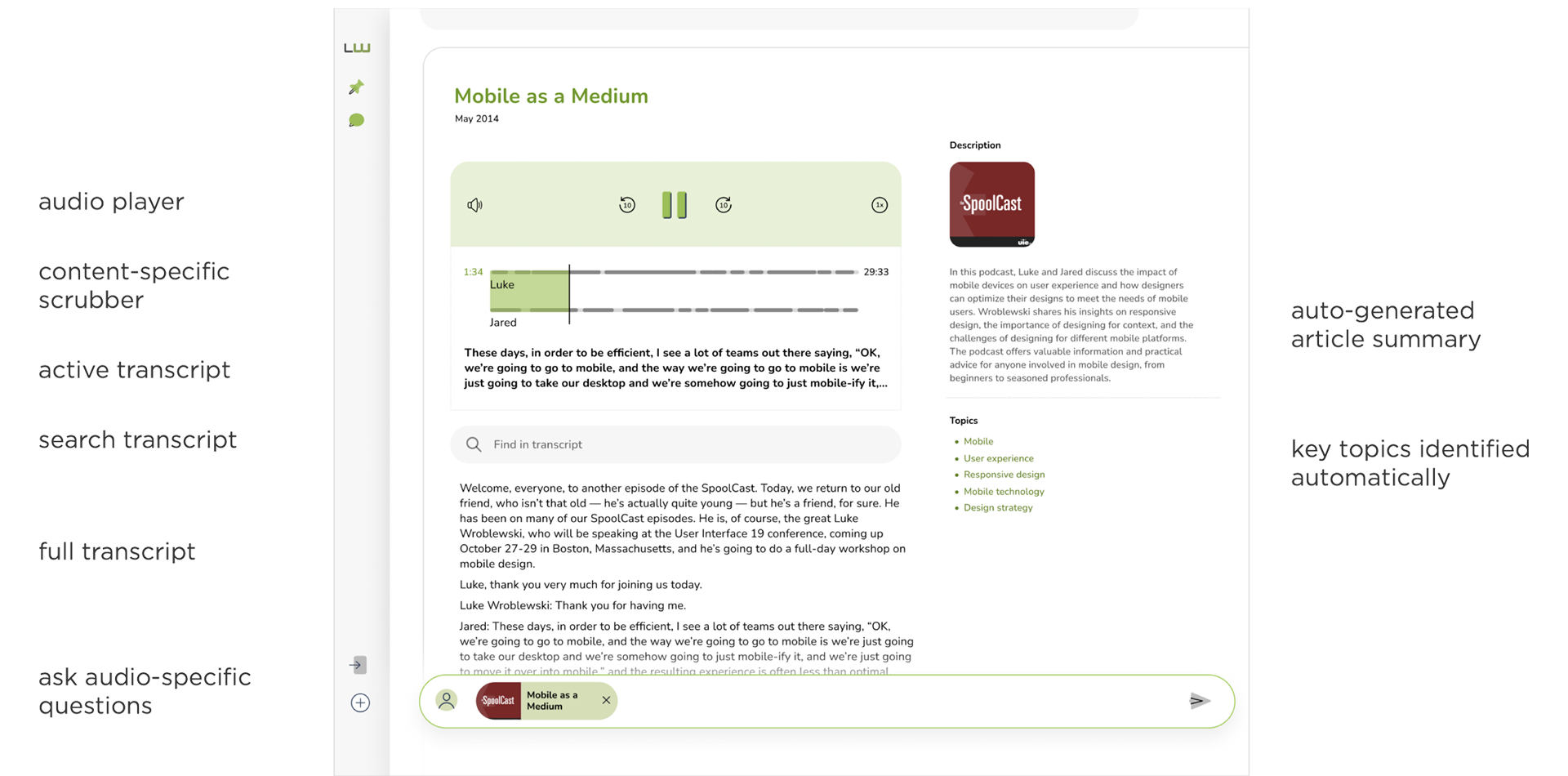
The inline player starting point is set to where the answer is mostly sourced from. I say "mostly" because a LLM generated answer may pull from multiple points in an audio file to create a response, so we start you in the right vicinity of the topic being discussed. Below the audio player is an indication of who is speaking that also serves as a scrubber to let you move through the file with context. A full, speaker separated transcript follows that's generated by using an automatic speech recognition AI model.

This integrated audio experience follows our general approach of providing content-specific tools within a conversational interface. For both articles and audio files selecting the source card to the right of a generated answer takes you into that deeper experience.
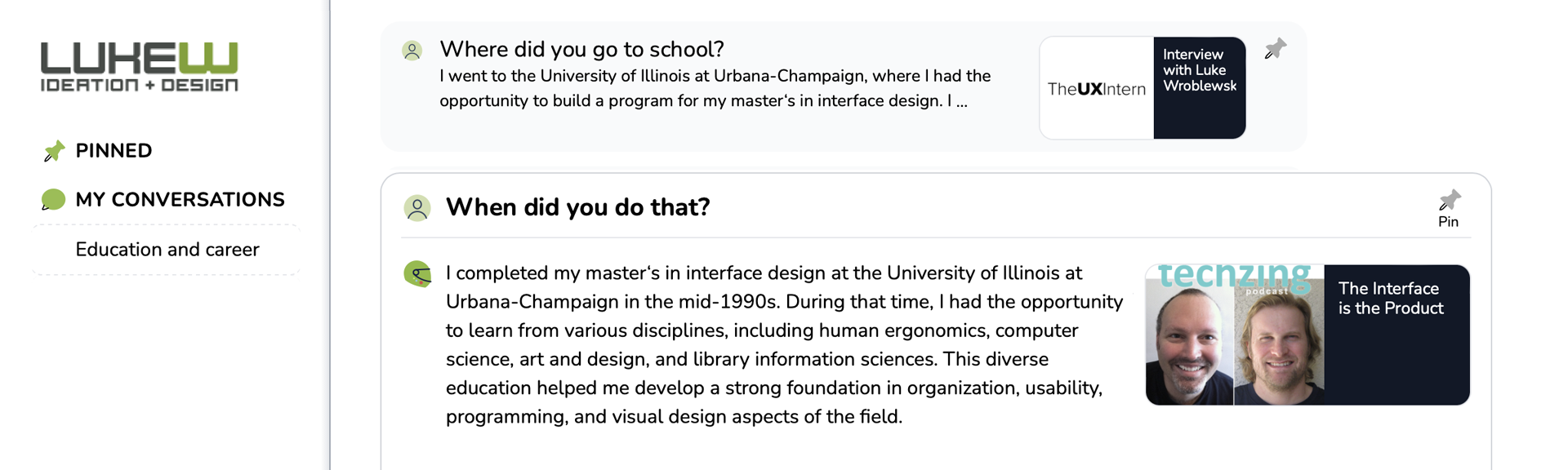
Last but not least, we also added some conversational memory to Ask LukeW. Now most references to previous questions will be understood so you can more naturally continue a conversation.
As before, much thanks to Yangguang Li (front end), Thanh Tran (design), and Sam Pullara (back end) in helping this exploration move forward.