Over the years, I've given more than 300 presentations on design. Most of these have been accompanied by a slide deck to illustrate my points and guide the narrative. But making the content in these decks work well with the Ask Luke conversational interface on this site has been challenging. So now I'm trying a new approach with AI vision models.
To avoid application specific formats (Keynote, PowerPoint), I've long been making my presentation slides available for download as PDF documents. These files usually consist of 100+ pages and often don't include a lot of text, leaning instead on visuals and charts to communicate information. To illustrate, here's of few of these slides from my Mind the Gap talk.

In an earlier article on how we built the Ask Luke conversational interface, I outlined the issues with extracting useful information from these documents. I wanted the content in these PDFs to be available when answering people's design questions in addition to the blog articles, videos and audio interviews that we were already using.
But even when we got text extraction from PDFs working well, running the process on any given PDF document would create many content embeddings of poor quality (like the one below). These content chunks would then end up influencing the answers we generated in less than helpful ways.
To prevent these from clogging up our limited context (how much content we can work with to create an answer) with useless results, we set up processes to remove low quality content chunks. While that improved things, the content in these presentations was no longer accessible to people asking questions on Ask Luke.
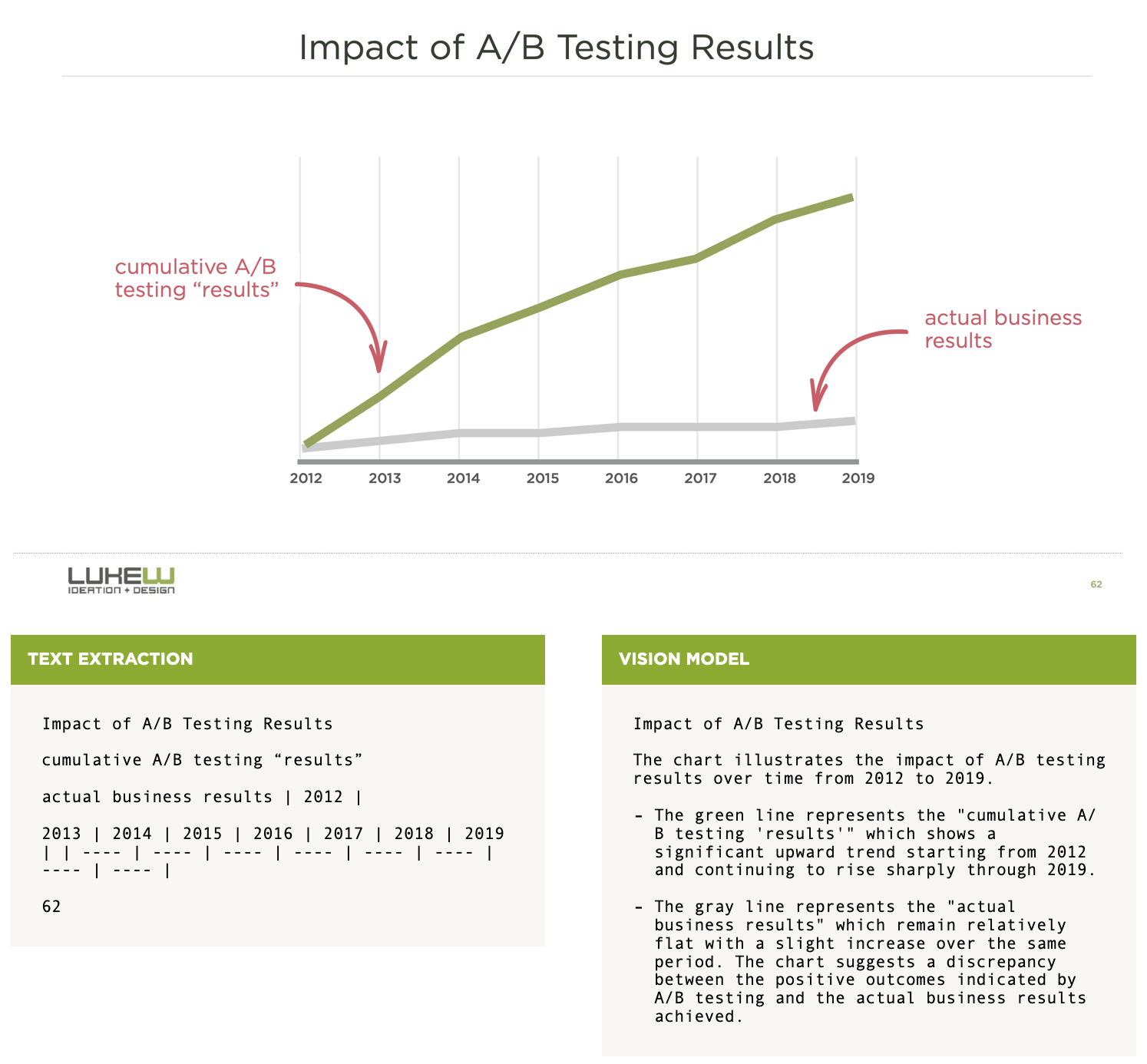
So we tried a different approach. Instead of extracting text from each page of a PDF presentation, we ran it through an AI vision model to create a detailed description of the content on the page. In the example below, the previous text extraction method (on the left) gets the content from the slide. The new vision model approach (on the right) though, does a much better job creating useful content for answering questions.
Here's another example illustrating the difference between the PDF text extraction method used before and the vision AI model currently in use. This time instead of a chart, we're generating a useful description of a diagram.

This change is now rolled out across all the PDFs the Ask Luke conversational interface can reference to answer design questions. Gone are useless content chunks and there's a lot more useful content immediately available.
Thanks to Yangguang Li for the dev help on this change.