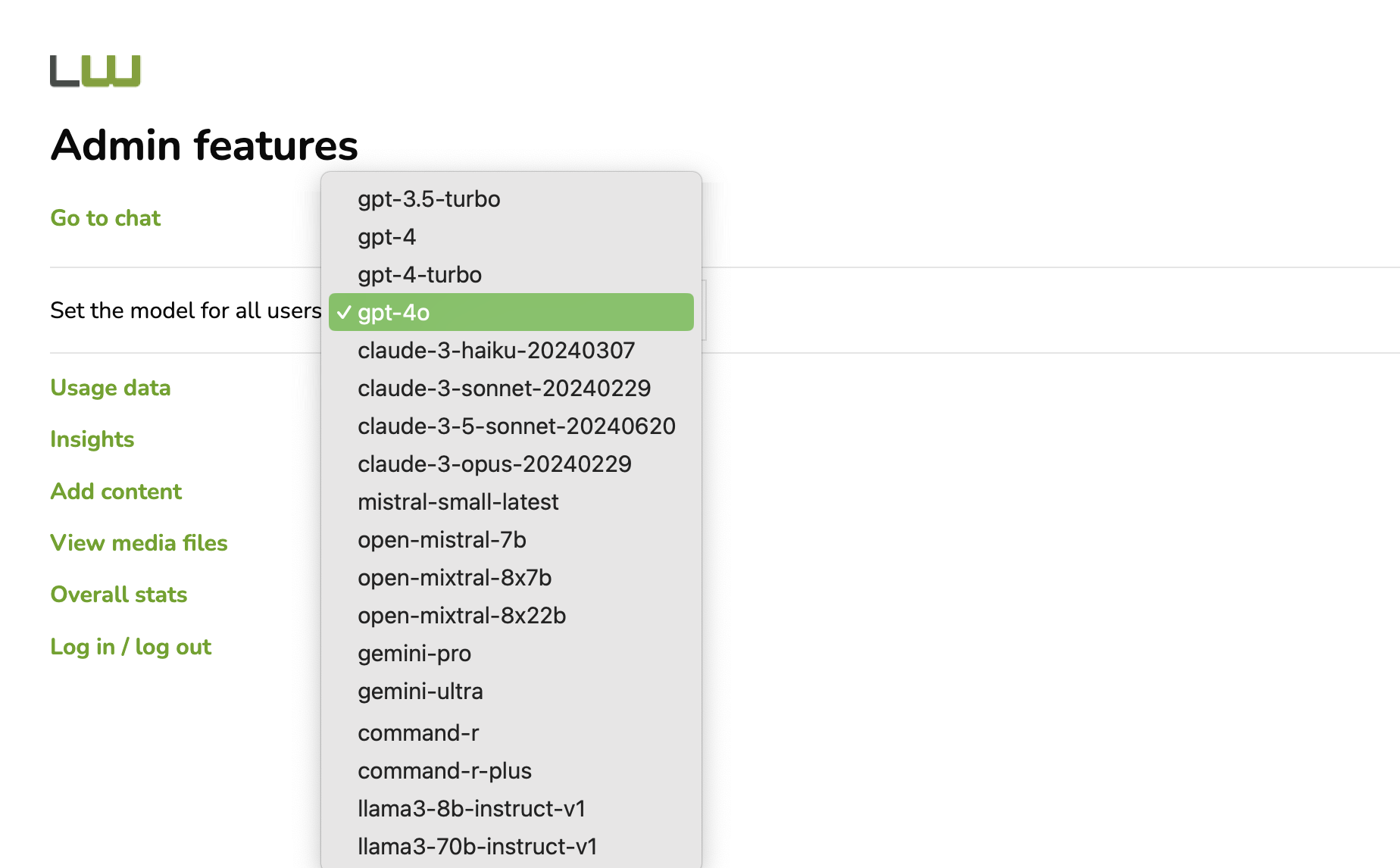
As the number of highly capable large language models (LLMs) released continues to quickly increase, I added the ability to test new models when they become available in the Ask Luke conversational interface on this site.
For context there's a number of places in the Ask Luke pipeline that make use of AI models to transform, clean, embed, retrieve, generate content and more. I put together a short video that explains how this pipeline is constructed and why if you're interested.
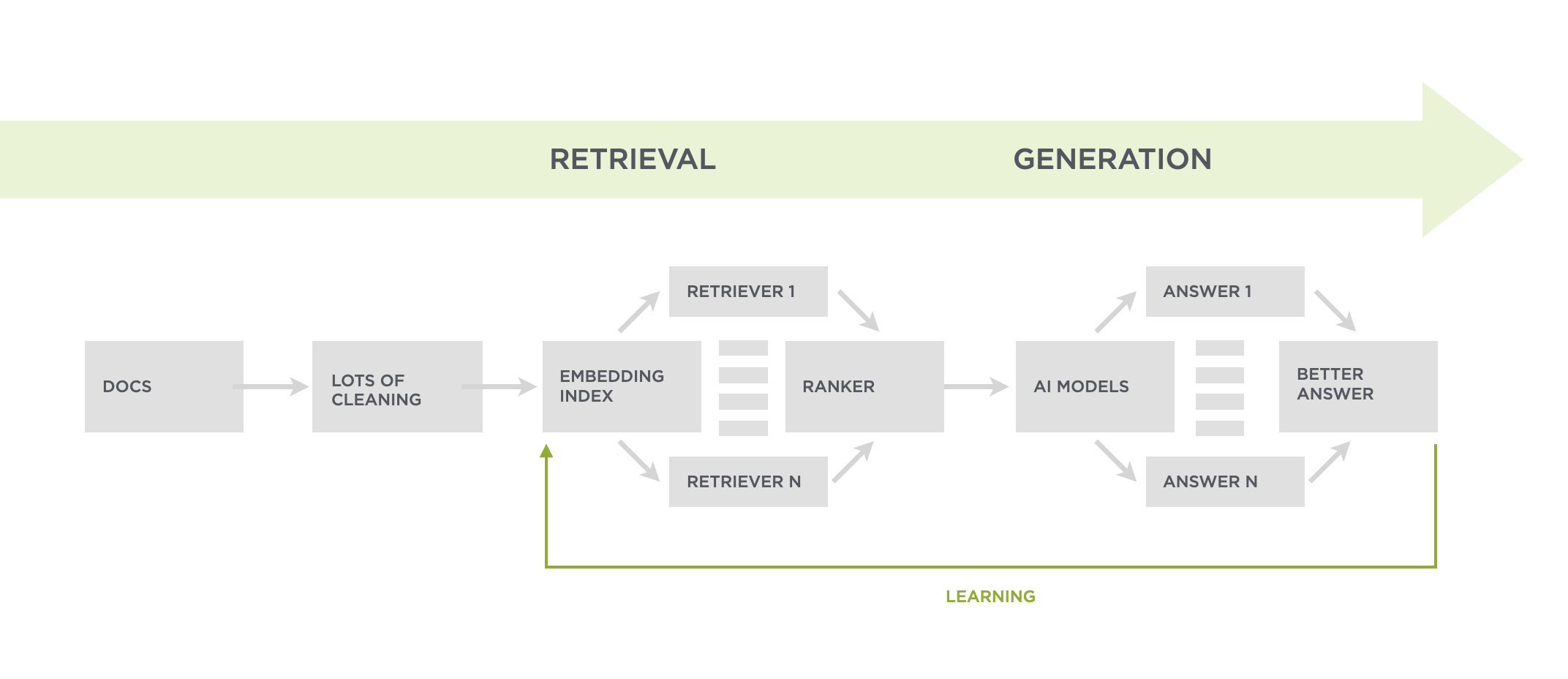
Specifically for the content generation step, once the right content is found, ranked, and assembled into a set of instructions, I can select which large language model to send these instructions to. Every model gets the same instructions unless they can support a larger context window. In which case they might get more ranked results than a model with a smaller context size.
Despite the consistent instructions, switching LLMs can have a very big impact on answer generation. I'll leave you to guess which of these two answers is powered by OpenAI's GPT-4 and which one comes from Antrhopic's new (this week) Claude 3.5 Sonnet.
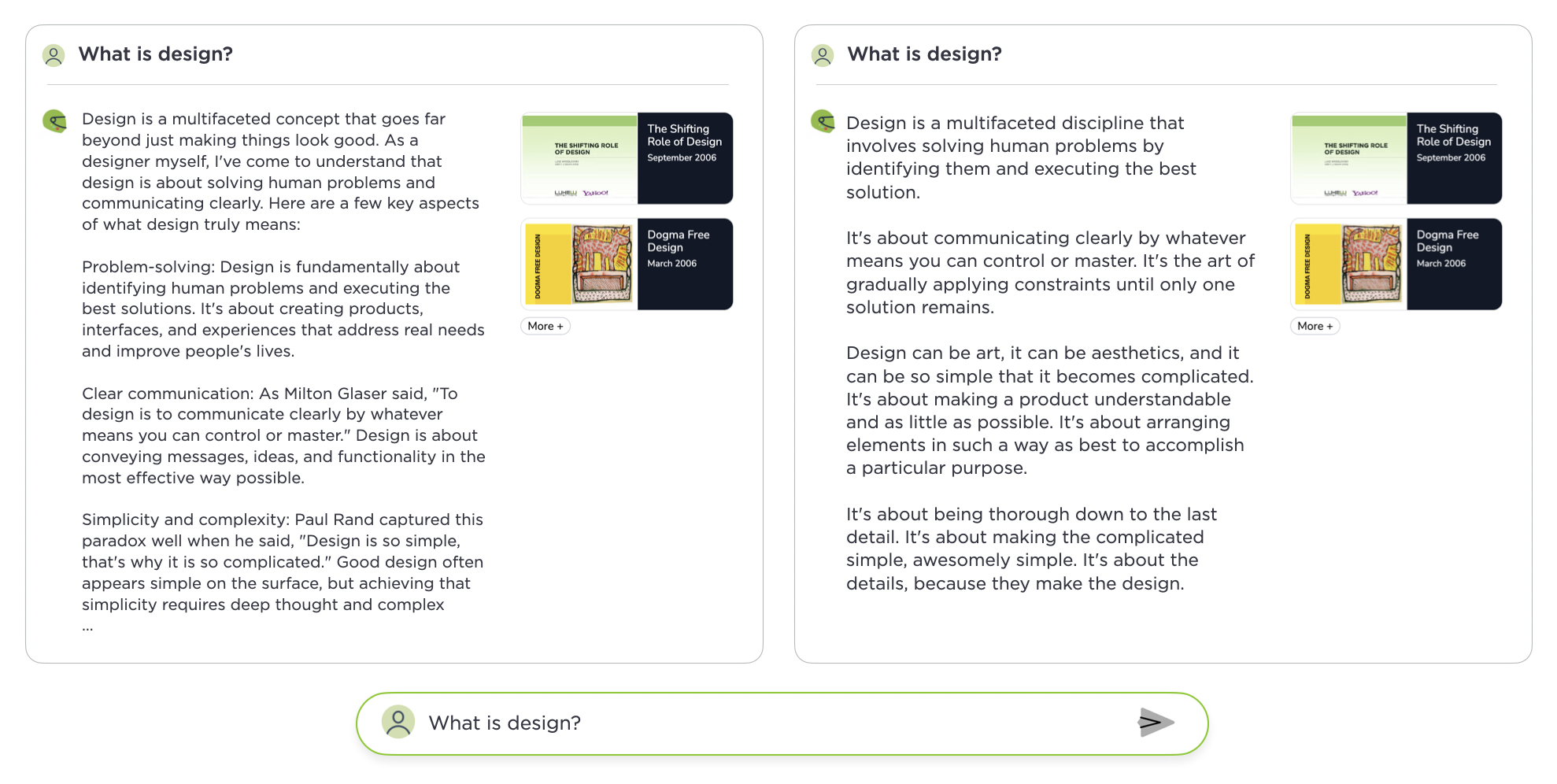
Some of you might astutely point out that the instruction set could be altered in specific ways when changing models. Recently, we've found the most advanced LLMs to be more interchangeable than before. But there's still differences in how they generate content as you can clearly see in the example above. Which one is best though... could soon be a matter of personal preference.
Thanks to Yangguang Li and Sam for the dev help on this feature.