With growing belief that we're quickly moving to a world of personalized multi-modal software assistants, many companies are working on early glimpses of this potential future. Here's a few ways you can explore bits of what these kinds of interactions might become.
But first, some context. Today's personal multi-modal assistant explorations are largely powered by AI models that can perform a wide variety of language and vision tasks like summarizing text, recognizing objects in images, synthesizing speech, and lots more. These tasks are coupled with access to tools, information, and memory that makes them directly relevant to people's immediate situational needs.
To simplify that, here's a concrete example: faced with a rat's nest of signs, you want to know if it's ok to park your car. A personal multi-modal assistant could take an image (live camera feed or still photo), a voice command (in natural language), and possibly some additional context (time, location, historical data) as input and assemble a response (or action) that considers all these factors.
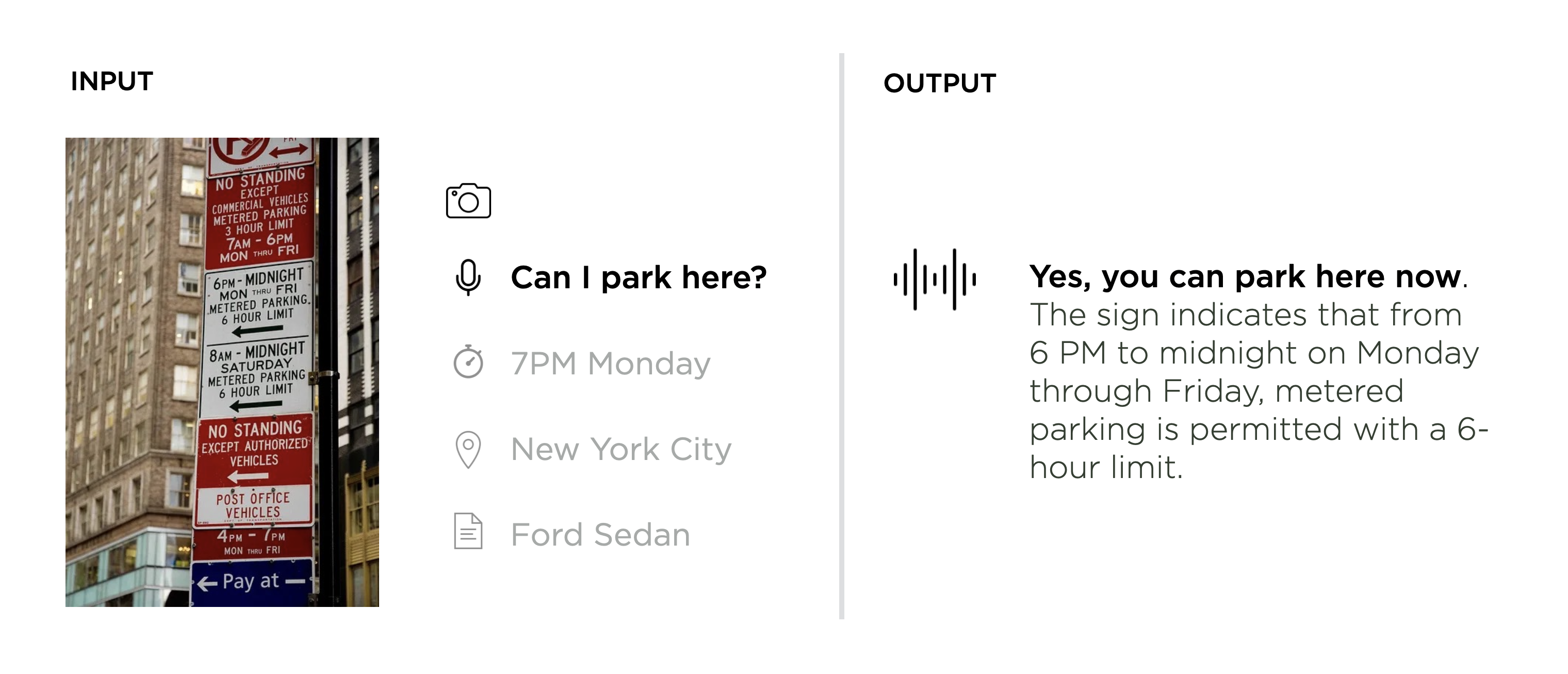
So where can you try this out? As mentioned, several companies are tackling different parts of the problem. If you squint a bit at the following list, it's hopefully clear how these explorations could add up to a new computing paradigm.
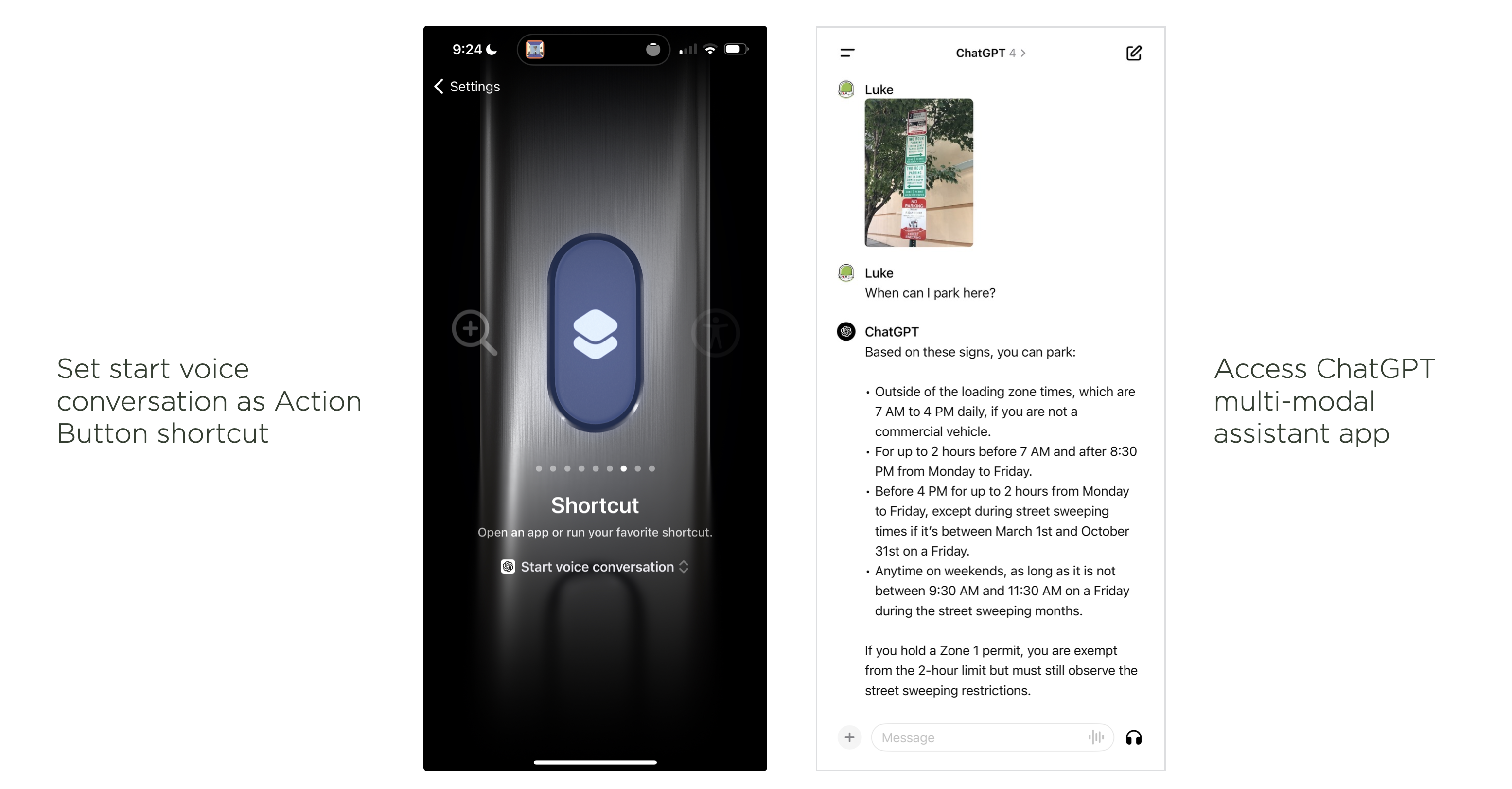
OpenAI's native iOS app can take image and audio input and respond in both text and speech using their most advanced large language model, GPT4... if you sign up for their $20/month GPT+ subscription. With an iPhone 15 Pro ($1,000+), you can configure the phone's hardware action button to directly open voice control in OpenAI's app. This essentially gives you an instant assistant button for audio commands. Image input, however, still requires tapping around the app and only works with static images not a real-time camera feed.
Humane's upcoming AI Pin (preorder $699) handles multiple inputs with a built in microphone, camera, touch surface, and sensors for light, motion, GPS, and more. It likewise, makes use of a network connection ($24/month) and Large Language Models to respond to natural language requests but instead of making use of your smartphone screen and microphone for output, it makes use of it's own speaker and laser projection display. Definitely on the "different" end of hardware and display spectrum.

Rewind's Pendant (preorder for $59) is a wearable that captures what you say and hear in the real world and then transcribes, encrypts, and stores it on your phone. It's mostly focused on the audio input side of a multi-modal personal assistant but the company's goal is to make use what the device captures to create a "personalized AI powered by truly everything you’ve seen, said, or heard."
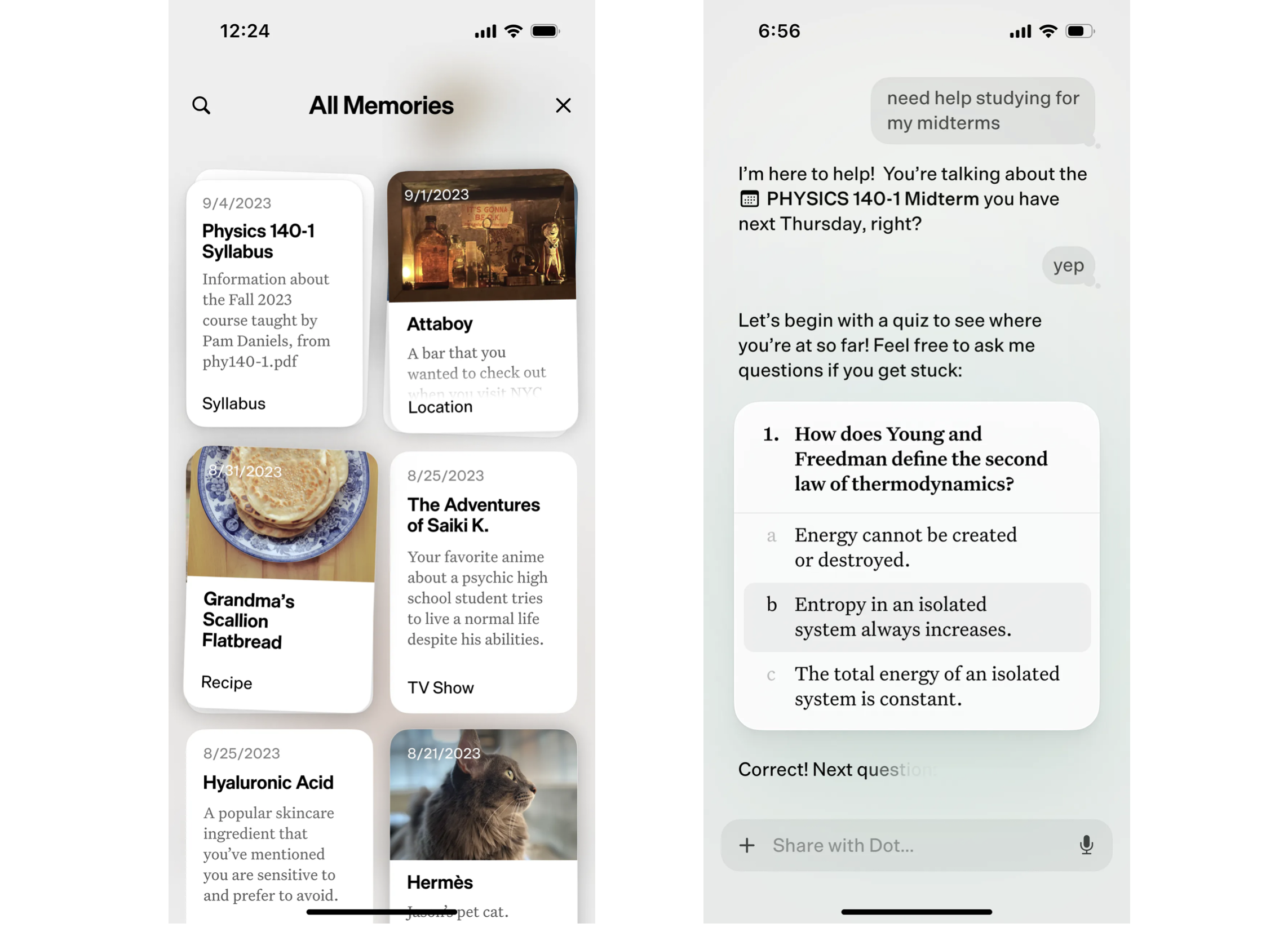
New Computer's Dot app (not yet available) has released some compelling videos of a multi-modal personal assistant that runs on iOS. In particular, the ability to add docs and images that become part of a longer term personal memory.
While I'm sure more explorations and developed products are coming, this list let's you touch parts of the future while it's being sorted out... wrinkles and all.