Blogs have permeated just about every corner of human interest from arphids to zoology and continue to grow at a furious pace. Despite their popularity, many blogs suffer from interface design shortcomings. Unlike issues of spam and authority, these problems have relatively straightforward solutions that could considerably increase the utility of blog content.
Assuming a blog is not filled with spam content (splogs), spam comments, or spam trackbacks, there’s often a wealth of information to be found therein: information that is frequently buried deep within archives and comments. This article looks at ways to bring that information forward.
Archives
Most blog archives are represented by either a listing of dates, titles, or at best both. This lack of context makes it quite difficult to find or discover relevant content “buried” in the archives.
To address this issue, Jakob Nielsen recently recommended employing a categorization of blog posts (so users can find content related by subject matter), using clear titles, and including a list of popular (and thereby potentially valuable) posts. Solid suggestions, but there’s ample opportunity to go further.
Effective ways to filter blog archives and contextual links included with blog posts can go a long way toward exposing valuable content to readers. Archives can be accessed by:
- Headline (title)
- Subject (tags and/or categories)
- Time (time, day, month, year)
- Author (of post, of comments)
- Format (links, reviews, articles)
- Popularity (incoming links, comments, trackbacks, traffic, ratings)
- Editorial Selection
- Continuum (how an idea develops over time)
Let’s see some of these concepts in action.
Tags
Browsing by subject matter (categories) can be enriched through the use of tagging. Due to its flexibility, tagging enables entries to appear within multiple “categories”. Simply assign multiple tags (keywords) to a single blog post and enable visitors to browse blog archives by tags.

Tags also provide a compelling entry point into archives when surfaced where they are contextually relevant (at the end of a related blog post). Multiple tags in this location are more likely than a single category to provide a path of interest for readers.
It’s worth noting that a local collection of tags should be actively managed. Because unique tags are so simple to create, it’s relatively easy to end up with a large number of tags that are used only once, which doesn’t help readers find more content. Nielsen made this point when discussing categories:
“Categories must be sufficiently detailed to lead users to a thoroughly winnowed list of postings. At the same time, they shouldn't be so detailed that users face a category menu that's overly long and difficult to scan. Do use categorization, but avoid the common mistake of tagging a posting with almost all of your categories. Be selective. Decide on a few places where a posting most belongs.” - Weblog Usability: The Top Ten Design Mistakes

An effective way to keep your local tag cloud under control is to display the tags you’ve already utilized on the “create post” page. This list lets you pick from already existing tags and can even be used to pre-fill tag input fields.
Formats
Blog posts usually fall into several distinct formats. Some posts are full-fledged articles with substantial content, some are simply pointers (links) to content found elsewhere, some are announcements, some are reviews (of books, movies, events, etc.), and some are compilations of content published in various locations. These formats can be identified with particular tags (announcement, article, review, link, etc,) or a consistent data field that may be used to filter a blog archive down to a specific format of interest. For instance: “I only want to see articles.”

Continuums
Blog continuums add a contextually relevant path for readers interested in seeing how a particular idea has continued to evolve. They look forward and see if any posts dated after the current post reference it. These links can then be displayed alongside the referenced post providing direct access to a continuation of an idea.

A fuller story can be told graphically. Blog continuum sparklines plot the current post a reader is viewing, the previous posts it references, and the later posts that reference it. This paints a picture of where the current post originated (what ideas it draws from), and where it went (how those ideas evolved).

Comments
Enhancing the interface design of a blog’s archives enables the author’s content to extend its shelf life and provides compelling content-specific browse experiences for readers. Improving the interactions found within blog comments, on the other hand, enables smoother navigation through the conversations generated by a post and surfaces ideas and content found therein.
Filters
Blog comments are a chronologically organized list of author praise, tangential discussions, flame wars, personal anecdotes, link dissemination, points and counterpoints, and valuable additions to the original post’s content. Just like blog archives, however, there’s rarely a good way to separate the signal from the noise.
In many cases, simply traversing comments chronologically adds a lot of overhead to basic information retrieval. For example, when viewing a technical “how-to” post, readers often scan the comments for corrections, alternative tips and techniques, or pointers to other helpful references. In most cases, they have to explicitly dig these valuable comments out of a vat of irrelevance.
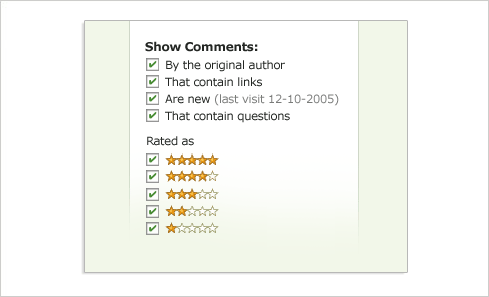
As a result, it could be quite helpful to filter a long list of comments by:
- Quality (the most useful, insightful, or relevant comments)
- Contains links (pointers to additional reference or related information)
- History (skip what I read last time I visited)
- Favorites (revisit comments I found valuable)
- Format (opinions, questions, modifications, etc.)
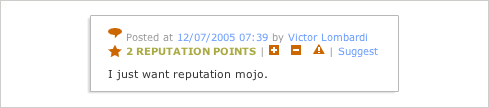
As an example, Boxes & Arrows recently implemented a comment rating system. Direct inline actions enable readers to flag comments as useful (+), not useful (-), and offensive (!). The most useful comments “rise to the top” of the comments list.
Conversational Flow
Sometimes the value within comments can’t be made visible through filtering. It exists within back and forth conversations between comment authors and/or the author of the original post. Unfortunately, this discussion is also likely to be interwoven between praise, flame, and tangent so following the conversation can become difficult.
This challenge is multiplied by a lack of visual assistance. Standard online discussion forums often display conversational threads visually (through indentation). This gives readers a sense of the depth and progression of a discussion. The free-form commenting style on blogs forgoes this structure in an effort to make discussion as simple as possible (there’s no need to consider which thread a new comment belongs to).
Though developing threaded visualizations from a set of blog comments would be quite challenging, it may be possible to introduce basic sorting or navigation controls that reveal something about the structure of conversations found within comments. These could include:
- Discussion about a specific portion of the post
- Discussion about a specific comment
- Comments by the author of the post
As an example. Dunstan Orchard developed a feature that enabled readers to directly reference the specific comments to which they were responding. These relationships were then included in the context of each comment. In the example below, Dunstan was responding to an earlier comment by Papuass and two readers (Kev & Ian) later responded to his comment.
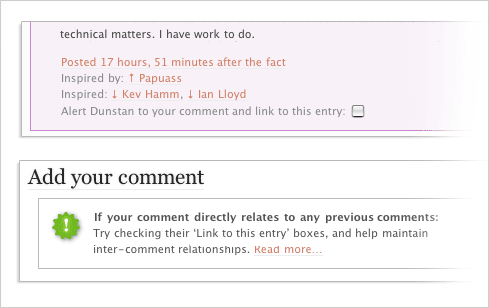
The direct links within the comment allow readers to bypass unrelated content and thereby more accurately follow conversational flow within comments.
Similarly, comments that quote specific portions of a post, could be referenced within the original post and lead directly to a filtered list of comments.

Getting the Data
There’s much to be said about how the archiving and commenting features described here can be implemented both by blog authors and readers. The creation and management of the metadata required to expose valuable content within blog archives and comments is not a trivial task.
Automated processes can help, but effective classification is often best left to real people. This doesn’t mean the burden needs to fall entirely on a blogger’s shoulders. Metadata creation could be:
- Entirely author controlled. All decisions about post categories, tags, related links, etc. come from the author. This has the advantage of eliminating malicious rating or tagging and puts the author’s perspective front and center.
- Author initiated and approved, but incorporate reader input through public systems for rating and tagging. Advantages include less work for the author (assuming no spam), and a greater sense of community around the blog if everyone can rate, tag, and categorize for the rest of the blog’s readers to use.
- Purely reader driven, no blog author involvement required.
Each approach can provide a foundation for the interface design concepts discussed in this article: concepts that get valuable content out of blog archives and comments and into the hands of readers -where they belong.